디스크 읽기 방식
컴퓨터의 CPU나 메모리처럼 전기적 특성을 띤 장치의 성능은 짧은 시간 동안 매우 빠른 속도로 발전했지만, 디스크 같은 기계식 장치의 성능을 상당히 제한적으로 발전했다. 비록 최근에는 자기 디스크 원판에 의존하는 HDD(하드 디스크 드라이브)보다 SSD가 많이 활용되고 있지만, 여전히 데이터 저장 매체는 컴퓨터에서 가장 느린 부분이다. 따라서 데이터베이스의 성능 튜닝은 어떻게 디스크 I/O를 줄이느냐가 관건일 때가 상당히 많다.
하드 디스크 드라이브(HDD)와 솔리드 스테이트 드라이브(SSD)
컴퓨터에서 CPU나 메모리 같은 주요 장치는 대부분 전자식 장치이지만 하드 디스크 드라이브(HDD)는 기계식 장치이다. 따라서 데이터베이스 서버에서 항상 디스크 장치가 병목이 된다.
이러한 기계식 HDD를 대체하기 위해 전자식 저장 매체인 SSD(Solid State Drive)가 나왔다. SSD는 기존 HDD에서 데이터 저장용 플래터(원판)를 제거하고, 그 대신 플래시 메모리를 장착하고 있다. 그래서 디스크 원판을 기계적으로 회전시킬 필요가 없으므로 아주 빨리 데이터를 읽고 쓸 수 있다. 또한 플래시 메모리는 전원이 꺼져도 데이터가 휘발되지 않는다. 물론 컴퓨터의 메모리(D-Ram)보다는 느리지만 기계식 하드 디스크 드라이브보다는 훨씬 빠르다.

시중에 판매되는 SSD는 대부분 기존 HDD보다 용량이 적으며 가격도 비싼 편이지만, 예전보다는 SSD가 훨씬 더 대중화된 상태이며 요즘은 DBMS용으로 사용할 서버에는 대부분 SSD를 채택하고 있다.
디스크의 헤더를 움직이지 않고 한 번에 많은 데이터를 읽는 순차 I/O에서는 SSD가 HDD보다 조금 빠르거나 비슷한 성능을 보인다. 하지만 랜덤 I/O에서는 SSD가 훨씬 빠른 성능을 보인다. 데이터베이스 서버에서 순차 I/O 작업은 그다지 비중이 크지 않고 랜덤 I/O를 통해 작은 데이터를 읽고 쓰는 작업이 대부분이므로 SSD는 DBMS용 스토리지에 최적이라고 볼 수 있다.
랜덤 I/O와 순차 I/O
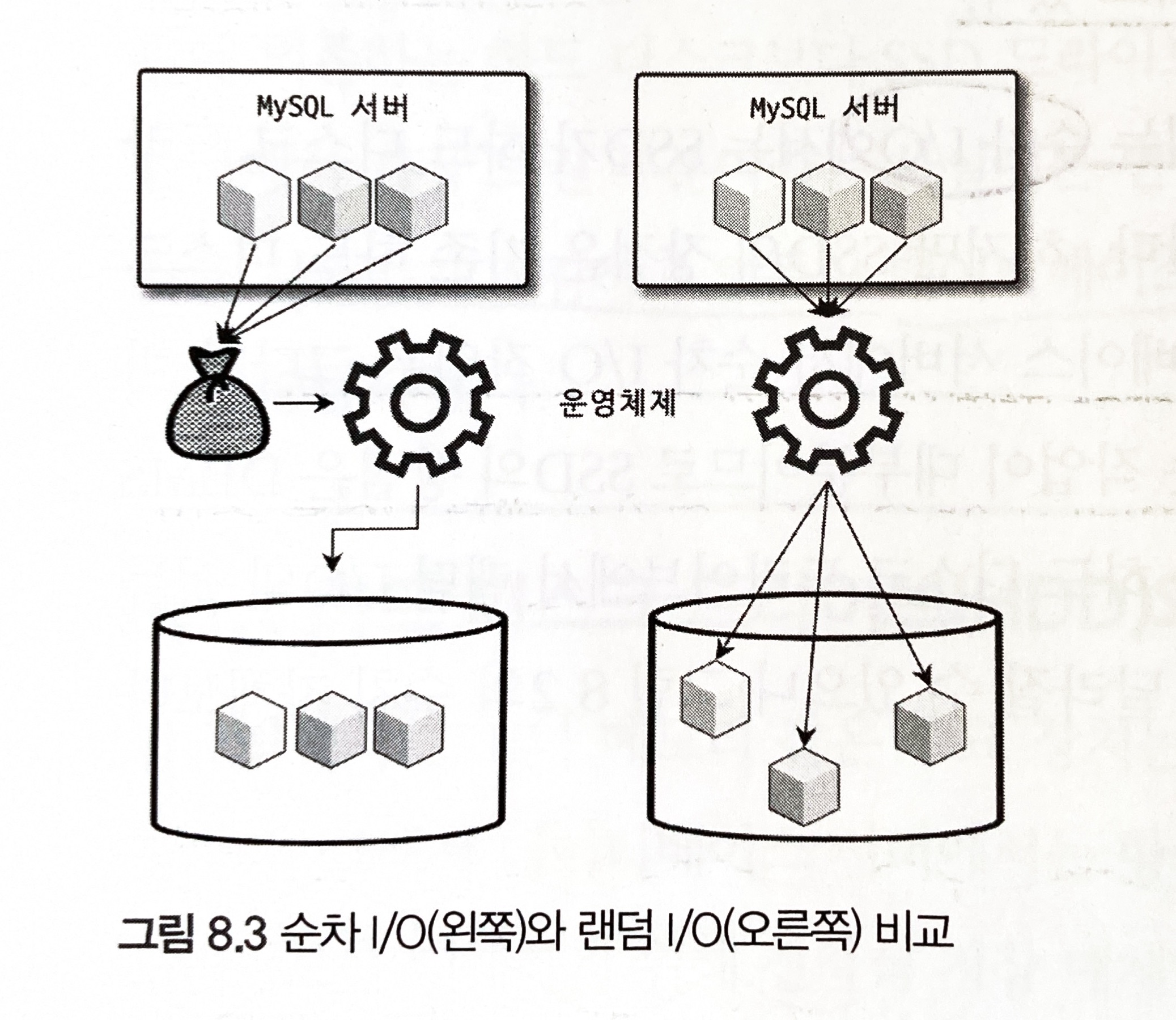
위 그림을 보면 순차 I/O는 3개의 페이지를 디스크에 쓰기 위해 1번 시스템 콜을 요청했지만, 랜덤 I/O는 3개의 페이지를 디스크에 쓰기 위해 3번 시스템 콜을 요청했다. 즉, 디스크에 쓸 위치를 찾기 위해 순차 I/O는 디스크 헤드를 1번 움직였고, 랜덤 I/O는 디스크 헤드를 3번 움직였다. 디스크에 데이터를 읽고 쓰는 데 걸리는 시간은 디스크 헤더를 움직이는 시간에서 결정된다. 따라서 순차 I/O가 랜덤 I/O보다 거의 3배 빠르다고 볼 수 있다.
즉, 디스크 성능은 디스크 헤더의 위치 이동 없이 얼마나 많은 데이터를 한 번에 기록하냐에 의해 결정된다고 볼 수 있다. 그래서 여러 번 쓰기 또는 읽기를 요청하는 랜덤 I/O 작업이 작업 부하가 훨씬 더 크다. 데이터베이스의 대부분의 작업은 이러한 랜덤 I/O 작업이므로 MySQL 서버에는 그룹 커밋이나 바이너리 로그 버퍼 또는 InnoDB 로그 버퍼 등의 기능이 내장되어 있다.
디스크 원판을 가지지 않는 SSD는 랜덤 I/O와 순차 I/O의 차이가 거의 없을 것 같지만 그렇지 않다. SSD에서도 랜덤 I/O는 순차 I/O보다 전체 스루풋(Throughout)이 떨어진다.
참고로, 인덱스 레인지 스캔은 데이터를 읽기 위해 주로 랜덤 I/O를 사용하지만, 풀 테이블 스캔은 순차 I/O를 사용한다. 그래서 큰 테이블의 레코드 대부분을 읽는 작업에서는 인덱스를 사용하지 않고 풀 테이블 스캔을 사용하도록 유도할 때도 있다. 이는 순차 I/O가 랜덤 I/O보다 훨씬 빨리 레코드를 읽어올 수 있기 때문이다.
인덱스란?
인덱스는 추가적인 쓰기 작업과 저장 공간을 활용하여 데이터베이스 테이블의 검색 속도를 향상시키기 위한 자료구조이다. DBMS가 데이터베이스 테이블의 모든 데이터를 검색해서 원하는 결과를 가져오려면 시간이 오래 걸린다. 그래서 칼럼 또는 여러 칼럼들의 값과 해당 레코드가 저장된 주소를 키와 값의 쌍으로 삼아 인덱스를 만드는 것이다.
- 인덱스는 칼럼 값을 기준으로 정렬되어 보관된다.
- 그런데 인덱스가 추가될 때마다 값을 정렬해서 보관해야하므로 그 과정이 복잡하고 느리다. (빠른 SELECT)
- 그러나 정렬되어 있기 때문에 값을 찾는 것은 빠르다. (느린 INSERT, UPDATE, DELETE)
- 결과적으로 DBMS에서 인덱스는 데이터의 저장(INSERT, UPDATE, DELETE)의 성능을 희생하고 그 대신 데이터의 읽기 속도를 높이는 기능이다.
- 따라서 테이블에 인덱스를 하나 더 추가할지 말지는 데이터의 저장 속도를 어디까지 희생할 수 있는지, 읽기 속도를 얼마나 더 빠르게 개선해야 할지에 따라 결정된다.
- WHERE 조건절에 사용되는 칼럼이라고 해서 전부 인덱스로 생성하면, 데이터 저장 속도가 느려지고 인덱스 크기가 비대해져 추가 저장 공간만 사용할 뿐이다.
Reference
- 위키북스, Real MySQL 8.0
'CS > Database' 카테고리의 다른 글
| [Real MySQL] 9. 옵티마이저와 힌트 (0) | 2024.03.19 |
|---|---|
| [Real MySQL] 8. 인덱스 - B-Tree, B+Tree, Hash 인덱스 (0) | 2024.03.18 |
| SQL 알아보기 (0) | 2024.03.14 |
| 데이터베이스 기본 개념 (0) | 2024.03.06 |
| 관계형 데이터베이스(RDB) vs 비관계형 데이터베이스(NoSQL) (0) | 2024.03.04 |


