프로젝트에서 게시글 페이징 조회 시 게시글 데이터 뿐만 아니라 게시글의 좋아요, 댓글, 북마크 수를 함께 반환해야 했다. 따라서 게시글과 연관된 좋아요/댓글/북마크 엔티티를 함께 조회하면서 N+1 문제가 발생했다. N+1 문제를 해결한 과정은 다음과 같다.
1. 페치 조인
가장 대표적인 N+1 문제 해결 방안으로 패치 조인이 있다. 그러나 일대다, 다대다 관계인 컬렉션 페치 조인은 주의할 점이 있다. 바로 offset, limit 등의 키워드를 통한 페이징 처리가 DB에서 이뤄지지 않고, 조인 결과 전체가 메모리로 로드되고 애플리케이션 단에서 페이징 처리가 이뤄진다는 점이다.
그 이유는, 컬렉션 페치 조인 시 데이터 수가 의도치 않게 증가하게 되기 때문이다. 예를 들어, 게시글 1에 좋아요가 2개, 게시글 2에 좋아요가 2개라고 가정하자. 페치 조인을 하면 DB에서 조인이 발생하는데, 이때 조인 결과는 4개의 레코드가 된다.
- 게시글 1 + 좋아요 1
- 게시글 1 + 좋아요 2
- 게시글 2 + 좋아요 3
- 게시글 2 + 좋아요 4
만약 2개의 데이터를 페이징 조회할 경우, DB에서 페이징 처리가 이뤄지면 애플리케이션 단으로 게시글 1개와 좋아요 1, 2만 로드되게 된다.
즉, 컬렉션 페치 조인은 조인 시 데이터 수가 증가되는 문제가 있기 때문에 DB에서 offset, limit 등을 통한 정확한 페이징 처리가 불가하다. 따라서 DB에서 페이징 처리가 이뤄지지 않고 모든 데이터를 메모리로 불러와, 애플리케이션 단에서 페이징 처리가 이뤄지는 것이다. 따라서 컬렉션 페치 조인은 메모리 문제를 초래할 수 있다.
추가로, 데이터 수 증가 문제로 인해 컬렉션 페치 조인은 하나의 컬렉션에 대해서만 가능하고, 여러 개의 컬렉션에 대해서는 페치 조인 적용이 불가하다.
2. BatchSize
BatchSize를 설정하면 게시글과 연관된 좋아요/댓글/북마크 엔티티를 조회할 때 설정 사이즈만큼 하나의 쿼리로 조회하여 쿼리 수를 훨씬 줄일 수 있다. 즉, N+1 문제를 개선할 수 있다.
그러나 또 다른 문제가 발생하는데, 바로 연관된 엔티티의 수를 기준으로 정렬해서 조회하기 위해 각각의 메서드를 정의해야 한다는 것이다. 예를 들어, 게시글을 좋아요 순으로 정렬하여 페이징 조회할 경우, 다음과 같이 좋아요 순 정렬 메서드를 정의해야 한다.

JPA에서는 Pageable 객체를 통해 정렬 조건마다 메서드를 생성할 필요 없이 다양한 조건으로 조회를 할 수 있다. 그러나 Pageable 객체는 엔티티의 필드 값을 기준으로 정렬 및 페이징 처리를 제공한다. 그러나 좋아요/댓글/북마크는 게시글 엔티티의 필드가 아닌 연관된 엔티티이므로, 좋아요/댓글/북마크 순 정렬 페이징 조회를 위한 메서드를 각각 생성해야 한다.
3. 반정규화
따라서 좋아요/댓글/북마크 수를 게시글 엔티티의 필드로 추가하는 반정규화를 적용했다. 테스트를 통해 기존에 N+1 문제가 발생했을 때와 비교해보자. 우선 테스트 상황은 다음과 같다.
- 10만 건의 게시글과 10만 건의 게시글 중 랜덤하게 좋아요 10만 건을 INSERT 했다.
- jmeter를 통해 100명의 사용자가 10번 좋아요 순 정렬 게시글 페이징 조회 API를 호출한다.
- 참고로, 게시글 작성자 명은 외부 API를 통해 조회해오는데, 이 부분에 대한 오차를 없애기 위해 외부 API를 호출하지 않고 "use"로 표기했다.
3-1. 반정규화 적용 전
기존 코드는 다음 리포지토리 메서드를 통해 좋아요 순으로 게시글을 페이징 조회한다.

그리고 게시글의 댓글 수, 좋아요 수, 북마크 수를 post.getLikes().size()와 같이 연관된 엔티티가 몇 개인지 리스트 size를 통해 조회한다.

따라서 getSize() 호출 시 지연 로딩이 동작하며, 다음과 같이 N+1 문제가 발생했다.

테스트 결과, DB에서 조인이 일어나며 커넥션을 오래 잡고 있기 때문에 SQLTransientConnectionException 예외가 발생했다. (java.sql.SQLTransientConnectionException: HikariPool-1 - Connection is not available, request timed out after 5008ms.) 따라서 에러율이 65.9%가 나왔다. 참고로, DB hikari.connection-timeout을 5000ms로 설정했다.
그리고 Throughput은 16.2이 나왔다.

3-2. 반정규화 적용 후
반정규화를 적용한 후에는 Pageable 객체를 통해 좋아요 순으로 정렬 조회가 가능하기 때문에, 별도의 메서드는 정의하지 않아도 된다. 그리고 추가된 필드를 통해 댓글 수, 좋아요 수, 북마크 수를 조회한다.

따라서 다음과 같이 N+1 문제가 발생하지 않고, Pageable 객체를 통해 post 테이블에 대해서만 조회를 한다.
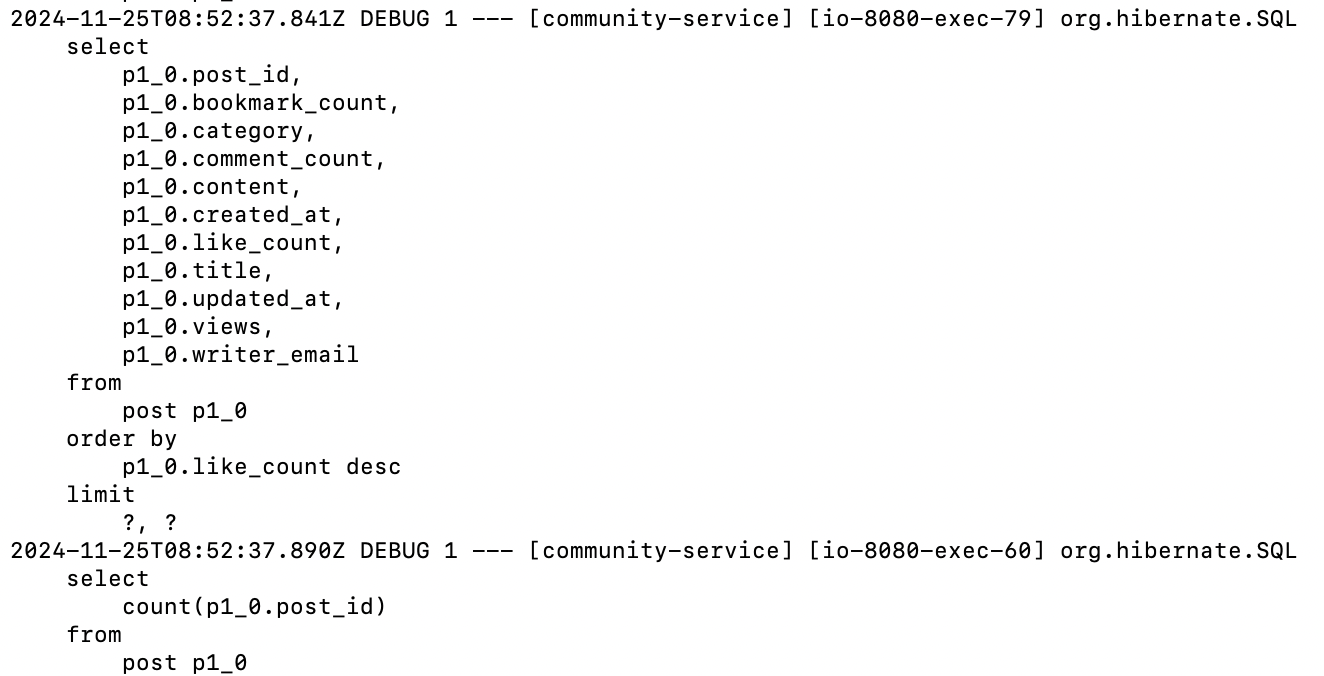
테스트 결과, 이전 방법과 달리 조인이 발생하지 않기 때문에 DB 커넥션을 오래 잡고 있지 않아서 에러율이 확연히 줄었으며, Throughput도 늘었다.

결과적으로 Throughput이 16.2에서 36.1로 약 122.84% 개선되었다.
'프로젝트' 카테고리의 다른 글
| 게시글 목록 조회 시 좋아요 수를 보여주는 구현 전략 (0) | 2024.11.26 |
|---|---|
| 예약 동시성 제어 과정 (0) | 2024.08.20 |
| 반정규화를 통한 성능 향상 (0) | 2024.05.21 |
| 프로젝트 중 SpringSecurity 필터 체인에서 발생한 예외를 처리한 방법 (0) | 2024.01.23 |



