카프카의 탄생 배경
카프카는 미국의 대표적인 소셜 네트워크 서비스인 링크드인에서 처음 시작된 기술로, 링크드인 서비스가 급속도로 성장하면서 발생하게 된 여러 이슈들을 해결하기 위해 탄생했다. 링크드인 서비스가 성장하면서 어떤 상황에서 어떤 새로운 시스템에 대한 개발 요구가 높아졌길래 카프카가 탄생하게 된 것일까?
다음 그림은 카프카가 개발되기 전 링크드인의 시스템 구성도이다.

카프카 등장 전에는 각 서비스가 엔드투엔드로 연결되어 있었다. 이러한 엔드투엔드 연결 방식의 아키텍처는 많은 문제점이 있었다.
- 첫 번째로, 통합된 전송 영역이 없으니 시스템 복잡도가 증가할 수밖에 없다. 따라서 문제를 발견하기 위해서는 이와 관련된 여러 데이터 시스템을 확인해야 했다.
- 두 번째로, 데이터 파이프라인 관리의 어려움이다. 실시간 트랜잭션 데이터베이스, 아파치 하둡, 모니터링 시스템, 키-값 저장소 등 많은 데이터 시스템들이 있는데, 이 시스템에 저장된 동일한 데이터를 각 개발자나 개발 부서는 각기 다른 방법으로 파이프 라인을 만들고 유지하게 되었다. 따라서 처음에는 각자의 목적에 맞게 만들어서 간편했지만, 시간이 지나면서 이 데이터 파이프라인들은 통합 데이터 분석을 위해 서로 연결되어야 하는 일들이 발생하게 된다. 하지만 각 파이프라인별로 데이터 포맷과 처리하는 방법들이 완전히 달라서 데이터 파이프라인은 확장하기 어려워졌고, 이러한 데이터 파이프라인들을 조정하고 운영하는 데에 엄청난 노력이 필요했다. 게다가 복잡성으로 인해 두 시스템 간의 데이터가 서로 달라져 데이터의 신뢰도마저 낮아졌다.
이렇게 복잡도가 늘고 파이프라인이 파편화되면서 개발이 지연되고 데이터 신뢰도가 떨어지는 상황에 이르자, 링크드인은 다음 목표를 가지고 새로운 시스템인 카프카를 만들었다.
- 프로듀서와 컨슈머의 분리
- 메시징 시스템과 같이 영구 메시지 데이터를 여러 컨슈머에게 허용
- 높은 처리량을 위한 메시지 최적화
- 데이터가 증가함에 따라 스케일아웃이 가능한 시스템
카프카 적용 이후 링크드인의 시스템 구성도는 다음과 같다.

카프카가 전사 데이터 파이프라인으로 동작하기 때문에 모든 데이터 스토어와 여기서 발생하는 데이터/이벤트가 카프카를 중심으로 연결되어 있다. 새로운 데이터 스토어가 들어와도 서로 카프카가 제공하는 표준 포캣으로 연결되어 있어서 데이터를 주고받는 데 부담이 없다. 그래서 더운 상세하고 다양하게 데이터를 분석해서 더 좋은 서비스를 제공할 수 있게 되었다.
예를 들어, 회원 서비스에서 새로운 회원이 가입되었다는 메시지를 카프카로 전달한다고 가정하자. 그러면 이 메시지를 멤버십 서비스가 컨슘하여 새로운 회원에게 멤버십 포인트를 부여한다. 동시에 하둡이 이 메시지를 컨슘하여 해당 유저에 대한 데이터를 저장해 분석한다. 또한 동시에 로그 스태시(로그 수집 시스템)는 이 메시지를 컨슘하여 개발자가 디버깅할 때 사용할 수 있도록 로그를 생성한다. 카프카가 없었다면 회원 서비스가 멤버십 서비스, 하둡, 로그 스태시로 각각 다른 데이터 파이프라인을 통해 데이터를 전송해야 했을 것이다(엔드투엔드). 반면 카프카를 사용하여 데이터 흐름을 중앙화하면 복잡도가 낮아질 수 있다.
다음 그림은 개발 당시 목표로 삼았던 카프카의 지향점을 나타낸다.
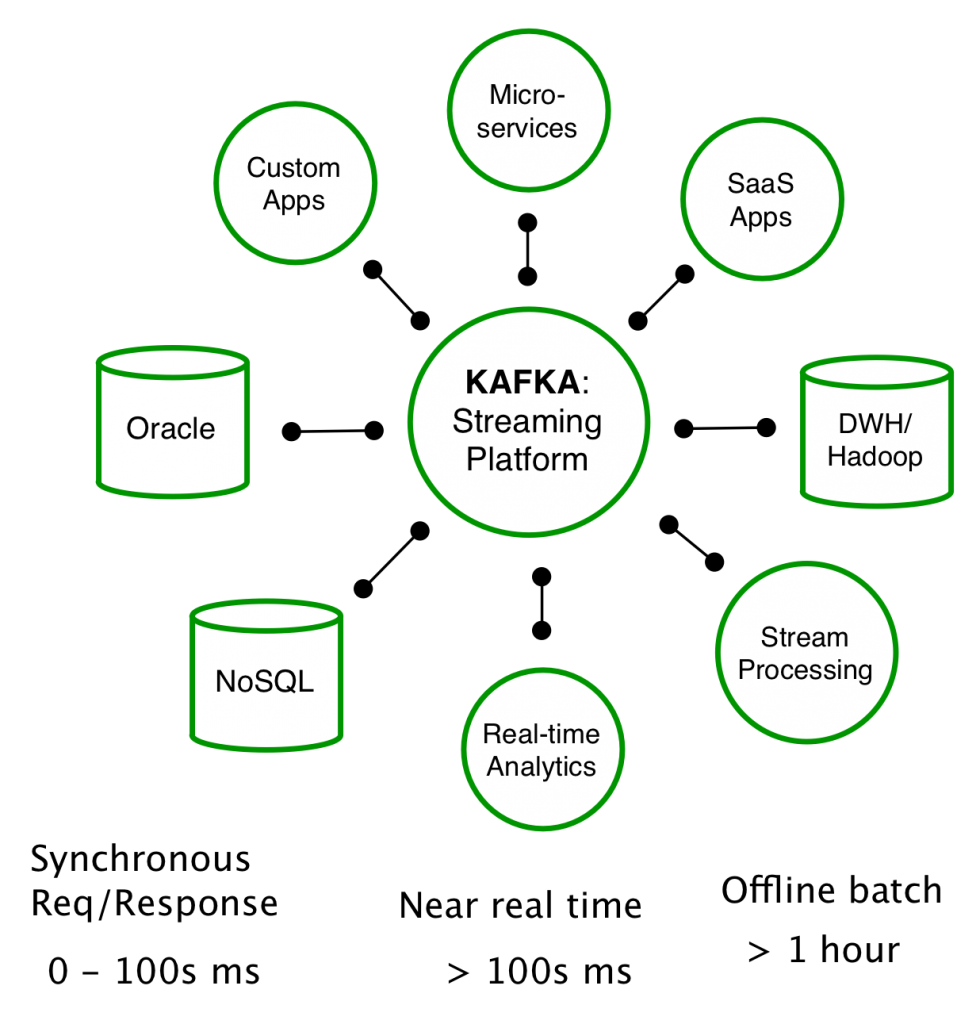
그림으로 알 수 있듯이 카프카를 메시지 전달의 중앙 플랫폼으로 두고 기업에서 필요한 모든 데이터 시스템(오라클과 같은 실시간 트랜잭션, NoSQL, 실시간 분석 시스템, 스트림 처리 시스템, 하둡, 데이터 웨어하우스) 뿐만 아니라 마이크로서비스, 사스 서비스 등과 연결된 파이프라인을 만드는 것을 목표로 두고 개발되었다. 그리고 이 같은 철학은 카프카 로고 이미지에 그대로 반영되었다.

카프카의 동작 방식과 원리
카프카는 기본적으로 메시징 서버로 동작한다. 따라서 카프카의 동작 방식을 이해하기 전에 먼저 메시징 시스템에 대해 이해해야 한다.
메시징 시스템
메시징 시스템에서 메시지를 보내는 측을 프로듀서(producer)라고 하고, 메시지를 가져가는 측을 컨슈머(consumer)라고 한다. 그리고 중앙에 메시징 시스템 서버를 두고 이렇게 메시지를 보내고(publish) 받는(subscribe) 형태의 통신을 pub/sub 모델이라고 한다.
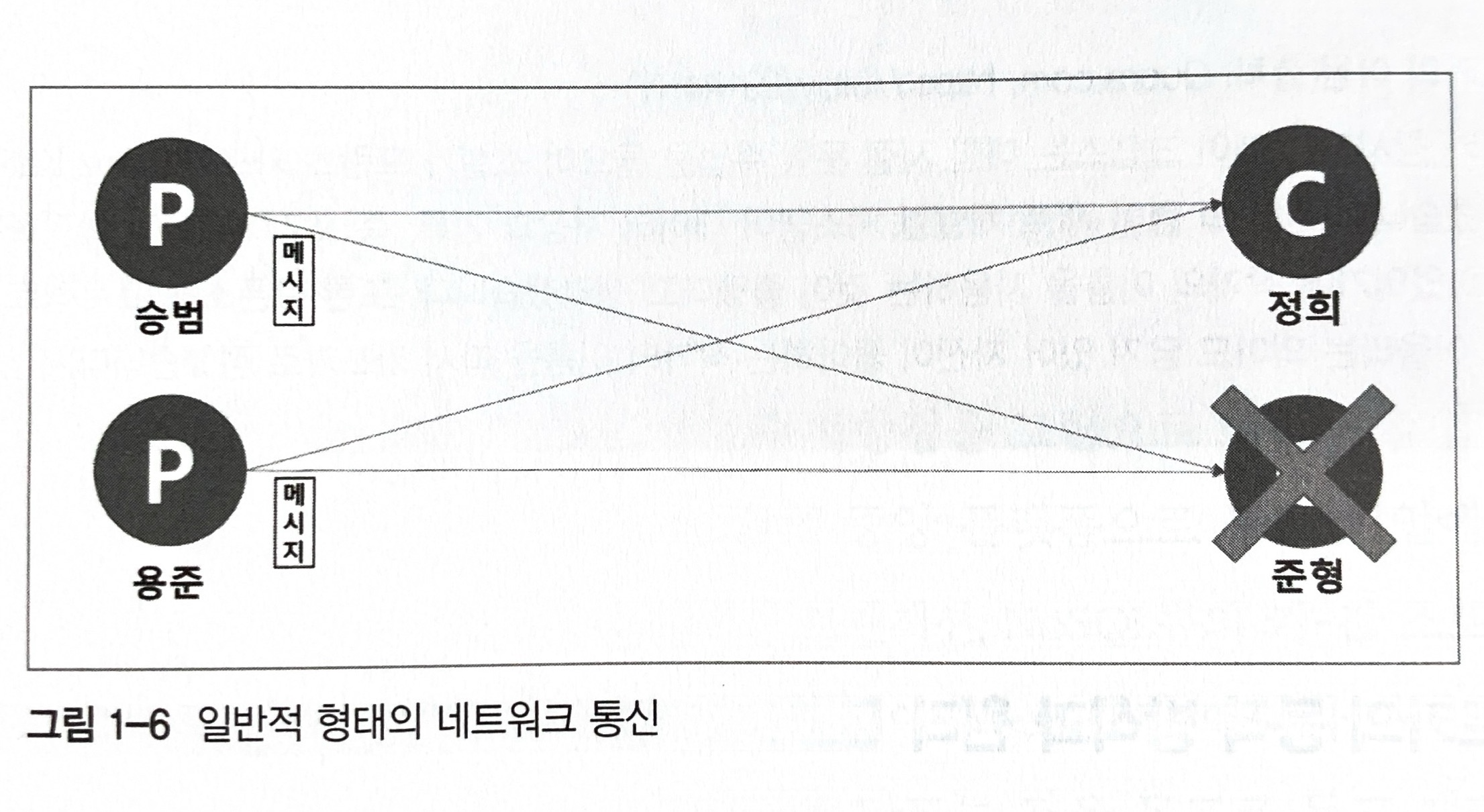

메시징 시스템을 사용하여 pub/sub 모델을 구현하면 다음과 같은 장점이 있다.
- 발신자와 수신자가 서로 직접 의존하지 않고 중간에 메시지 큐를 두기 때문에 느슨한 결합이 가능하다. 발신자와 수신자가 서로 의존하지 않고 메시지 큐를 중심으로 연결되어 있기 때문에 확장성이 좋다.
- 수신자 서비스에 장애가 발생하더라도 메시지 큐에 메시지가 보관되어 있기 때문에 한 번 전달된 메시지가 유실되지 않는다. 그리고 수신자 서비스가 회복되면 다시 메시지를 가져갈 수 있다.
- 메시지 큐를 사용하면 비동기 통신을 구현할 수 있다.
기존 메시징 시스템과 카프카의 차이
카프카 역시 기존 메시징 시스템과 동일한 비동기 시스템이다. 그러면 카프카가 기존 메시징 시스템과 다른 점은 무엇일까?
기본 메시징 시스템을 사용하는 pub/sub 모델은 메시징 시스템을 통해 대규모 데이터를 전달하기보다는 간단한 이벤트를 전달하는데 주로 사용되었다. 왜냐하면 메시징 시스템 내부의 교환기의 부하, 각 컨슈머들의 큐 관리, 큐에 전달되고 가져가는 메시지의 정합성, 전달 결과를 정확하게 관리하기 위한 내부 프로세스가 아주 다양하고 복잡하기 때문이다. 즉, 기존의 메시징 시스템은 메시지의 보관, 교환, 전달 과정의 신뢰성을 보장하는 것에 중점을 맞췄기 때문에 속도와 용량 측면에서는 성능이 떨어졌다.
카프카는 기존 메시징 시스템이 지는 성능의 단점을 극복하기 위해 메시지 교환 전달의 신뢰성 관리는 프로듀서와 컨슈머 쪽으로 넘기고, 부하가 많이 걸리는 교환기 기능은 컨슈머가 만들 수 있게 함으로써 메시징 시스템 내에서의 작업량을 줄이고 절약한 작업량을 메시징 전달 성능에 집중시켜서 고성능 메시징 시스템을 만들었다.
다음 그림은 기존 메시징 시스템과 다른 카프카의 아키텍처를 간단히 표현한 그림이다.

카프카의 메시지 전달 순서는 다음과 같다.
- 프로듀서는 메시지를 카프카로 전달한다.
- 프로듀서가 보낸 메시지는 카프카의 컨슈머 큐(토픽)에 전달되어 저장된다.
- 컨슈머는 카프카 서버에 접속하여 메시지를 가져간다.
카프카의 특징
- 멀티 프로듀서, 멀티 컨슈머: 하나의 프로듀서가 하나 이상의 토픽으로 메시지를 보낼 수 있고, 컨슈머도 하나 이상의 토픽으로부터 메시지를 가져올 수 있다.
- 디스크에 메시지 저장: 카프카가 기존 메시징 시스템과 가장 다른 특징 중 하나는 바로 디스크에 메시지를 저장하고 유지하는 것이다. 카프카의 모든 메시지(레코드)는 로그 형식으로 디스크에 기록된다. 메시지는 프로듀서가 보낸 순서로 기록되어 순서가 보장되면서, 메시지의 위치 값(오프셋)으로 컨슈머가 소비한 메시지의 위치를 표시한다.
- 확장성: 카프카는 확장이 매우 용이하게 설계되어 있다. 최초에 카프카 클러스터 구성 시 적은 수로 시작하더라도 이후 트래픽 및 사용량 증가로 클러스터를 확장할 수 있다.
- 높은 성능: 카프카는 고성능을 유지하기 위해 내부적으로 분산 처리, 배치 처리 등 다양한 기법을 사용한다.
- Pull 기반 메시지 소비: RabbitMQ는 브로커가 컨슈머로 메시지를 Push 하는 방식인데 반해, 카프카는 컨슈머가 능동적으로 브로커로부터 메시지를 가져오는 Pull 방식을 취했다. 이로 인해 컨슈머는 처리 능력에 따라 메시지를 컨슘할 수 있기 때문에, 브로커로부터 압도당하지 않고 최적의 성능을 낼 수 있다.
카프카 아키텍처

- 클러스터: 하나 이상의 카프카 브로커들(서버)의 집합이다.
- 브로커: 카프카 시스템을 구성하는 개별 카프카 서버이다. 브로커는 프로듀서로부터 메시지를 받아 토픽에 저장하고, 컨슈머에 전달하는 역할을 한다. 브로커는 여러 개의 토픽을 가질 수 있다.
- 토픽: 메시지들의 특정 카테고리 또는 피드를 나타낸다. 토픽은 데이터를 카테고리화하여 관리할 수 있게 한다. 예를 들어, 다양한 종류의 이벤트나 메시지들을 서로 다른 토픽으로 분류할 수 있다. 또한 하나의 토픽은 여러 소비자가 구독할 수 있다. 토픽에 한번 추가된 데이터는 수정될 수 없다.
- 파티션: 토픽을 구성하는 하위 단위로, 토픽은 1개 이상의 파티션으로 나뉠 수 있다. 이를 통해 카프카의 확장성과 병렬 처리 능력을 향상시킨다. 레코드에 키가 없다면 라운드 로빈으로 파티션에 나뉘어 저장되고, 같은 키를 가진 레코드는 같은 파티션에 저장된다.
- 오프셋: 파티션에 저장된 레코드는 증가하는 정수 ID를 갖고, 이를 오프셋이라고 부른다. 오프셋은 0부터 시작하며, 파티션에 레코드가 저장될 때 마다 시퀀셜하게 증가한다. 특정 파티션의 각 레코드는 고유한 오프셋을 갖지만, 서로 다른 파티션 간에는 고유하지 않다. 파티션에서 데이터를 읽을 때 작은 것부터 큰 순서대로 읽는다.
- 레코드: 파티션에 저장되는 데이터이다. Key, Value, Timestamp, Compression Type, Optional Headers, Partition and Offset id 로 구성된다.
- 프로듀서: 카프카에 요청하여 토픽에 레코드를 추가하는 클라이언트이다. 카프카의 구성 요소가 아니며, 카프카 외부에서 카프카에 요청하는 애플리케이션이다.
- 컨슈머: 하나 이상의 파티션과 토픽으로부터 레코드를 읽어오는 클라이언트이다. 기본적으로 사용 가능한 가장 낮은 오프셋부터 높은 오프셋까지 순서대로 레코드를 읽어온다. 하나의 토픽의 여러 파티션으로부터 레코드를 읽어올 때는 순서가 보장되지 않는다. 파티션 0, 1, 2 로부터 레코드를 읽어올 때 파티션 0의 레코드만 바라봤을 때는 순서가 보장되지만, 읽어온 전체 레코드를 바라볼대는 파티션 0 ~ 2의 레코드가 순서와 상관없이 섞여있을 수 있다.
- 컨슈머 그룹: 동일한 컨슈머 인스턴스를 여러개 생성하여 컨슈머 그룹을 구성할 수 있다. 컨슈머 그룹을 구성하는 여러 컨슈머는 동일한 토픽의 각자 다른 파티션을 도맡아 메시지를 컨슘할 수 있다. 예를 들어 토픽 A에 파티션이 0, 1, 2 가 생성되어 있고, 컨슈머 그룹 A에 컨슈머 a, b, c가 있다고 가정하자. 이 경우 컨슈머 a는 파티션 0을, 컨슈머 b는 파티션 1을, 컨슈머 c는 파티션 2를 컨슘한다.
Reference
'Backend > Kafka' 카테고리의 다른 글
| 카프카 오프셋 커밋과 메시지 손실, DLT (0) | 2025.03.27 |
|---|
